25 Sep

À la fin de l’année 2022, ChatGPT, le modèle de langage d’OpenAI, a surpris tout le monde par ses capacités étonnantes. Sa génération de texte semblable à celle d’un être humain et sa compréhension approfondie de sujets divers ont laissé tout le monde stupéfait, démontrant son potentiel pour révolutionner diverses industries et remodeler l’interaction entre l’homme et la technologie.
En tant qu’entreprise centrée sur la connaissance, il est devenu évident qu’une évaluation approfondie était nécessaire pour imaginer comment il pouvait améliorer la façon dont nous gérons le contenu. Nous avons décidé d’explorer des moyens d’utiliser sa puissance pour multiplier les capacités de nos utilisateurs et leur offrir une expérience améliorée.
Hackathon
Pour mieux saisir l’intégration potentielle de ce nouvel outil, nous avons adopté une approche proactive en organisant un hackathon de deux jours impliquant toute l’entreprise. L’objectif était clair : développer des preuves de concept (POC) liés à notre produit, en intégrant l’intelligence artificielle.
Au cours du hackathon, nous avons généré plus de 30 idées de POC, examinant soigneusement leur faisabilité et leurs avantages potentiels pour nos utilisateurs finaux. Nous avons concentré nos efforts sur deux idées qui se sont démarquées comme à la fois réalisables et impactantes. Le premier concept impliquait la création automatique d’un podcast qui condensait et présentait les contenus clés, tandis que le deuxième concept était centré sur une fonction de questions-réponses.
La création de Answer
Munis des POCs et des idées, l’équipe produit a sollicité les retours des utilisateurs pour évaluer l’intérêt et l’impact potentiel. Il est devenu évident que la fonction de questions-réponses avait le potentiel de révolutionner vraiment notre produit. Les commentaires reçus des utilisateurs ont résonné fortement, indiquant que la fonction de questions-réponses pouvait grandement améliorer leur expérience avec le produit.
Cette prise de conscience a poussé l’équipe à donner la priorité au développement et à la perfectionnement de la fonction de questions-réponses, reconnaissant qu’elle changerait la manière dont les gens travaillent avec la base de connaissances, non seulement en obtenant des réponses plus rapides et de meilleure qualité en utilisant un langage naturel, mais aussi en changeant l’interaction entre le producteur et le consommateur du contenu, ce qui conduirait à une base de connaissances meilleure, plus correcte et plus précise.
Comment fonctionne Answer sous le capot
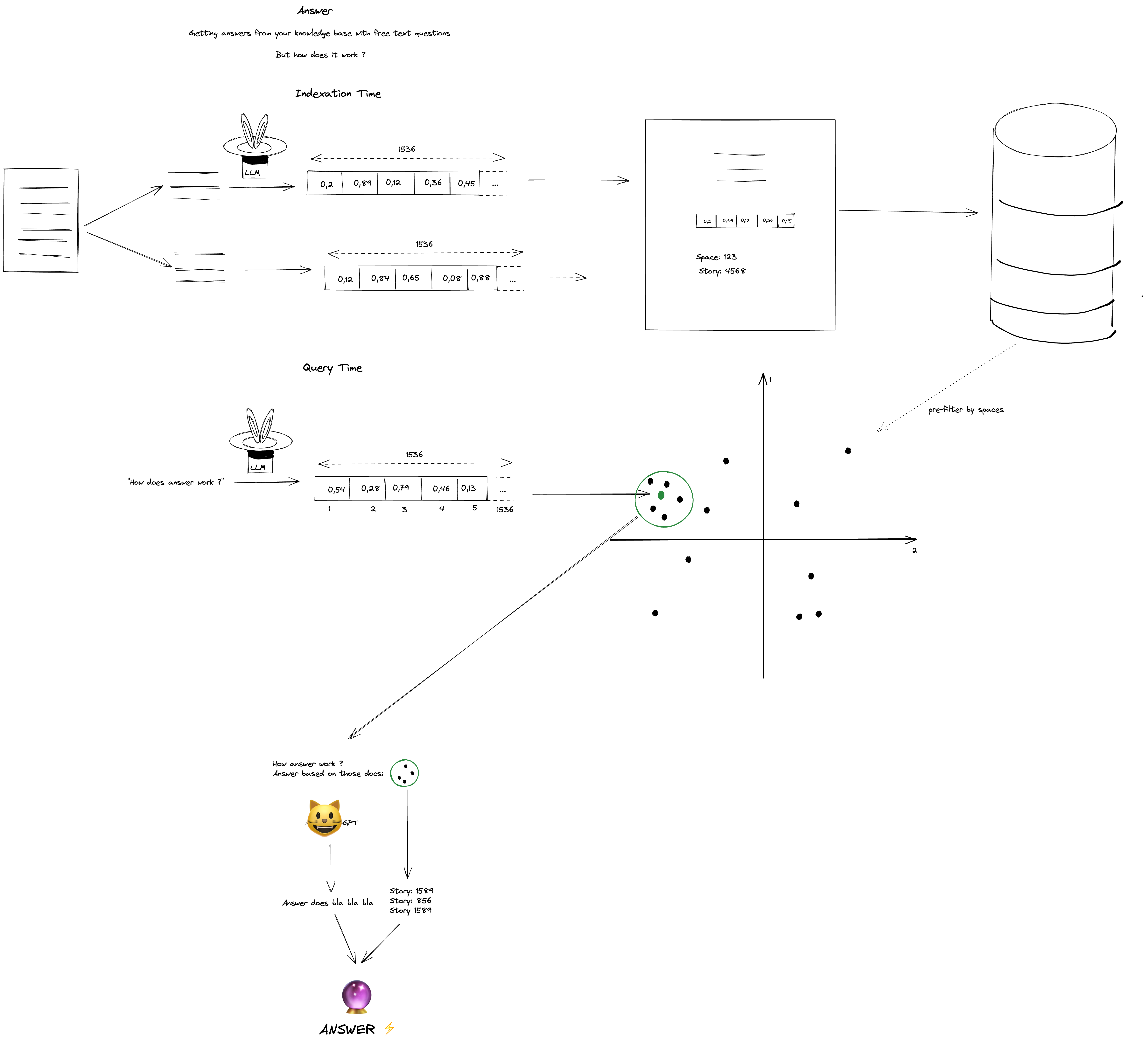
Cela représente l’ensemble du cycle de vie de Answer. Explorons-le en deux parties : le temps d’indexation et le temps de requête.
Temps d’indexation
Lorsqu’un contenu est sauvegardée dans l’application Elium, nous l’indexons sémantiquement pour capturer sa signification, plutôt que simplement les mots.
Pour ce faire, nous divisons le contenu en petits extraits d’environ 300 mots, tout en essayant de maintenir les limites des phrases. Pour chaque extrait, nous demandons à un modèle de langage de grande envergure (LLM) d’extraire l’embedding du passage.
Un embedding est un vecteur qui représente le sens de l’extrait.
Elle peut être visualisée comme la disposition des mots sur un graphique, comme s’il y avait un axe pour le formel contre informel, positif contre négatif, et plus encore, en utilisant le contexte pour capturer le sens.
Nous stockons l’embedding, le texte du passage et des métadonnées telles que l’ID du contenu, le titre, l’ID de l’espace, … dans l’index.
Temps de requête
Pendant le temps de requête, nous utilisons le même LLM pour calculer l’embedding de la requête. À partir de là, nous pouvons déterminer le document le plus proche de la requête grâce à des calculs mathématiques simples, en particulier la similarité cosinus entre l’embedding de la requête et l’embedding du document.
Nous pouvons trouver quelques documents les plus similaires à la requête à partir d’une ou de plusieurs contenus.
À ce stade, nous avons la possibilité de renvoyer ces documents, ce qui serait rentable, mais nous pouvons améliorer cela en fournissant à ChatGPT les documents que nous avons trouvés et en lui demandant de répondre à la question de l’utilisateur.
Voici un exemple simplifié de la prompte que nous utilisons.

Enfin, nous renvoyons la réponse de ChatGPT et la liste des contenus à partir desquelles les documents sont issus.

Conclusion
En conclusion, le développement de Answer a été une expérience remarquable pour notre équipe. Nous avons été confrontés à des défis et avons acquis des connaissances précieuses en cours de route. ChatGPT a élargi nos possibilités et a changé notre façon d’aborder le partage des connaissances. Le hackathon, les commentaires des utilisateurs et les aspects techniques de l’indexation sémantique et de l’embedding de requête ont tous contribué à la création de cette fonctionnalité innovante. À l’avenir, nous sommes impatients de voir comment Answer améliorera la manière dont nous aidons les gens à trouver les connaissances dont ils ont besoin.
Note : Le contenu suivant a été rédigé en utilisant notre dernière innovation, l’AI Editor. Une autre fonctionnalité captivante rendue possible avec la sortie de ChatGPT.







