20 Sep

In late 2022, ChatGPT, OpenAI’s language model, surprised everyone with its astonishing capabilities. Its human-like text generation and deep understanding of diverse subjects left everyone amazed, showcasing its potential to revolutionise various industries and reshape human-technology interaction.
As a company centred around knowledge, it became evident that a thorough evaluation was necessary to assess how it could improve the way we manage content. We decided to explore ways to harness its power to multiply our users’ capabilities and provide them with an enhanced experience.
Hackathon
To better grasp the potential integration of this new tool, we took a proactive approach by organising a two-day hackathon involving the entire company. The objective was clear: develop proof-of-concept (POC) projects related to our product, incorporating AI.
During the hackathon, we generated over 30 POC ideas, carefully examining their feasibility and potential benefits for our end users. We narrowed our focus to two ideas that stood out as both feasible and impactful. The first concept involved an automatically generated podcast that condensed and presented key stories, while the second concept centred around a Q&A feature.
The creation of Answer
Equipped with the POCs and ideas, the product team sought user feedbacks to gauge interest and potential impact. It became evident that the Q&A feature had the potential to be a true game changer. The feedback received from users resonated strongly, indicating that the Q&A feature could greatly enhance their experience with the product.
This realisation propelled the team to prioritise further development and refinement of the Q&A feature, recognising that it would change the way people work with the knowledge base, not only by having quicker and better response using natural language, but also change the interaction between producer and consumer of the content thus leading to better, more correct and precise knowledge base.
How does Answer work under the hood
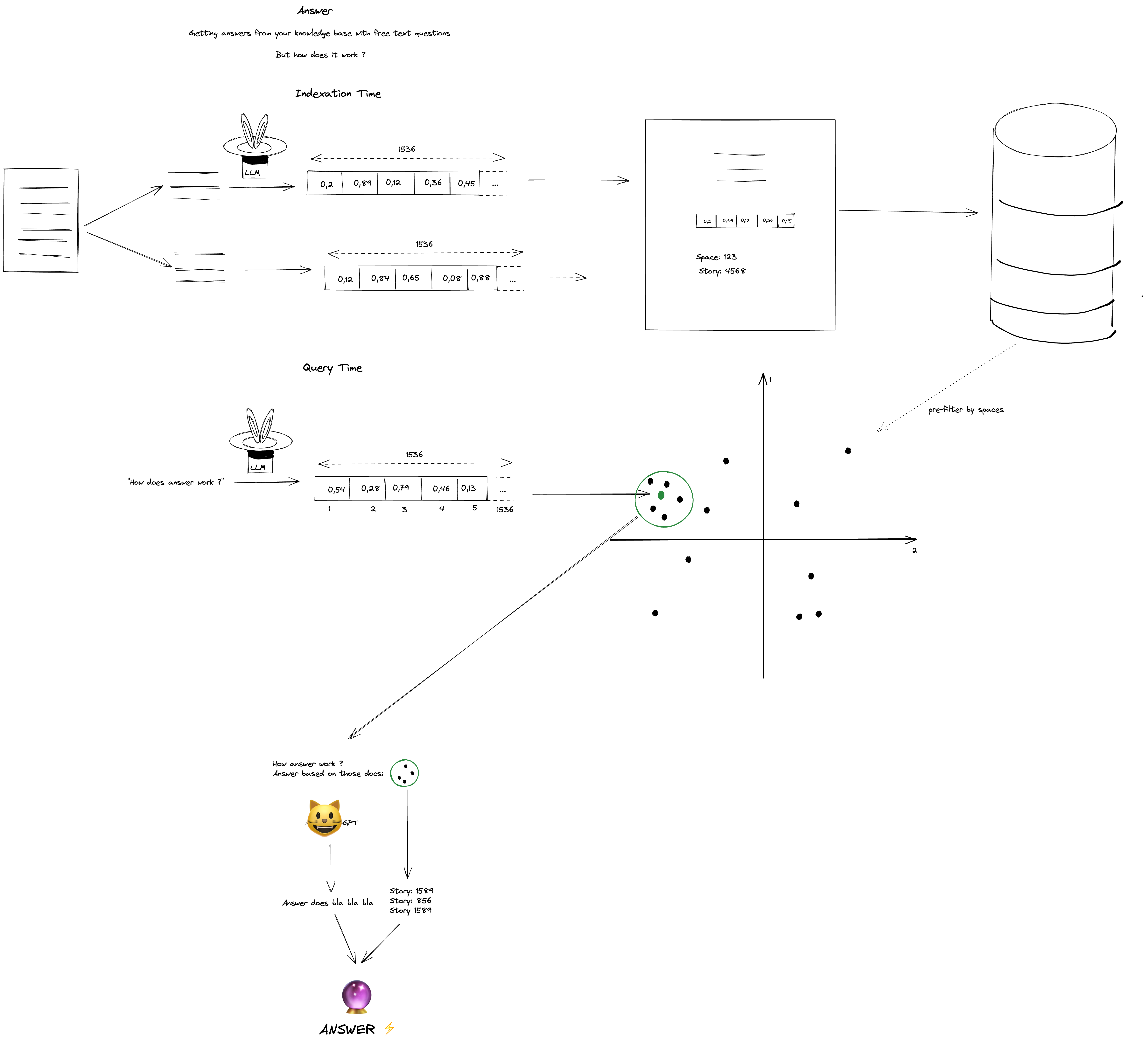
This represents the whole life cycle of Answer. Let’s break it down in two parts: index time and query time.
Index time
When a story is saved in the Elium app, we semantically index it to capture its meaning, rather than just the words.
To achieve this, we divide the story into smaller chunks of approximately 300 words, while attempting to maintain sentence boundaries. For each chunk, we request a large language model (LLM) to extract the embedding of the chunk.
An embedding is a vector that represents the meaning of the chunk.
It can be visualised as plotting words on a graph, as if there was an axis for formal vs informal, positive vs negative, and more, using context to capture meaning.
We store the embedding, the chunk text, and metadata such as story ID, story title, space ID, … in the index.
Query time
During query time, we utilise the same LLM to calculate the query embedding. From there, we can determine the document closest to the query through basic math, specifically the cosine similarity between the query embedding and document embedding.
We can find a few documents that are the most similar to the query from one or multiple stories.
At this stage, we have the option to return these documents, which would be cost-efficient, but we can improve upon this by providing ChatGPT with the documents we have found and request it to respond to the user’s question.
Here is a simplified example of the prompt we use.

Finally, we return the response of ChatGPT, and the list of stories from which the documents originated.

Conclusion
In conclusion, the development of Answer has been a remarkable experience for our team. We have faced challenges and gained valuable insights along the way. ChatGPT has expanded our possibilities and changed the way we approach knowledge sharing. The hackathon, user input, and technical aspects of semantic indexing and query embedding have all contributed to the creation of this innovative feature. Moving forward, we look forward to seeing how Answer will enhance the way we help people to find the knowledge they need.
Note: The following content was written using our latest innovation, the AI Editor. Another captivating feature made possible with the release of ChatGPT.
Gregory Culpin is Chief Commercial Officer at Elium. With an engineering degree from UCLouvain and an MBA from Solvay Brussels School, he has spent nearly two decades in SaaS scale-ups and consulting, shaping go-to-market strategy, customer success, and commercial operations. He writes on how enterprises structure knowledge for AI readiness, operational resilience, and sustainable growth.






Gregory Culpin